1 - IHPA (Intelligent HPA)
本节将展开介绍 IHPA 相关的基本概念和一些具体使用细节。
如果你还不知道什么是 IHPA,可以先阅读介绍。
如果你希望快速上手使用 IHPA 的核心功能,可以跟随快速开始。
1.1 - 概念
1.1.1 - IHPA 整体架构
组件架构图
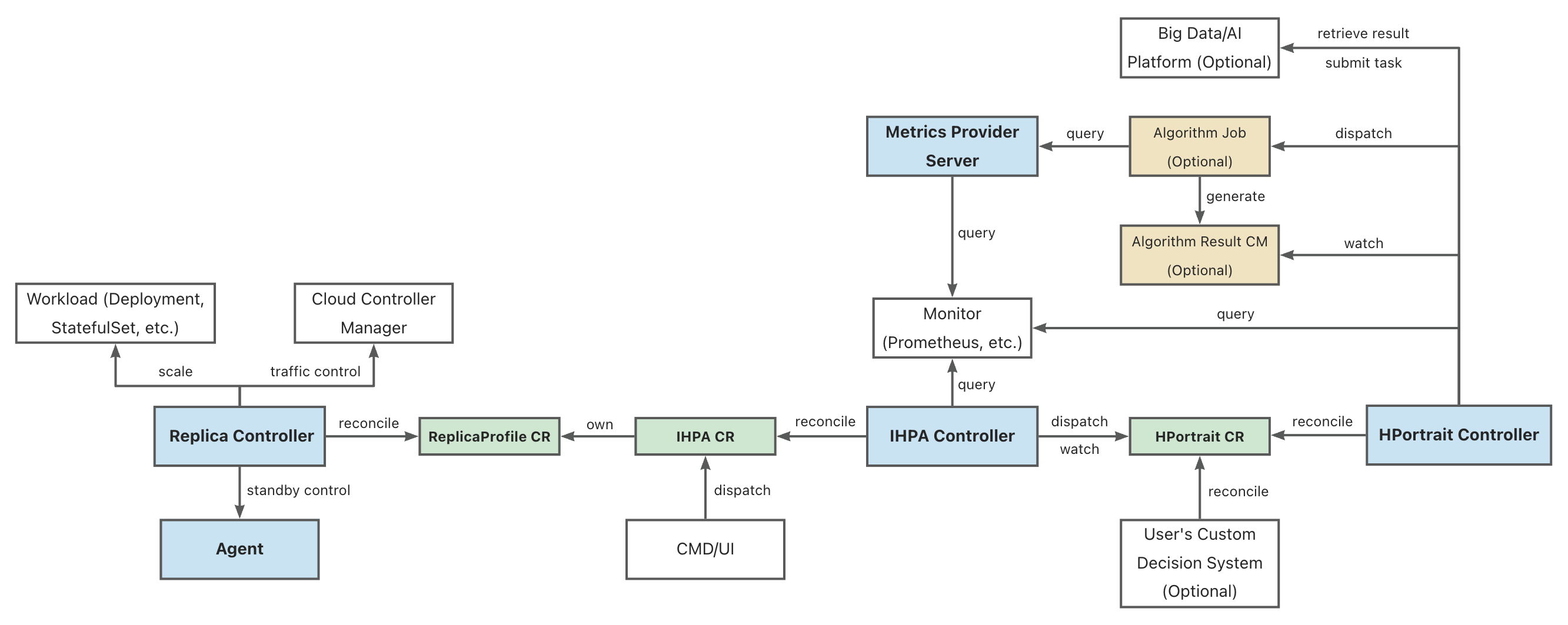
图例:
- 蓝底的为 IHPA 自身组件
- 绿底的为 IHPA 自身的 Kubernetes 定制资源(CR)对象
- 黄底的为 IHPA 依赖的其他 Kubernetes 资源对象
- 白底的为相关外部系统
部分缩写的全称:
- IHPA: IntelligentHorizontalPodAutoscaler
- HPortrait: HorizontalPortrait
- CM: ConfigMap
组件概述
Replica Controller
IHPA 执行层组件,负责具体工作负载副本数量和状态控制,其通过对接不同的原生和第三方组件支持 Pod 的扩缩容、摘挂流和激保活等操作。
IHPA Controller
IHPA 控制面组件,直接接受用户或外部系统的 IHPA 配置(包括目标工作负载、指标、算法、变更与稳定性配置等),下发画像任务并整合画像结果,再根据画像结果执行多级分批弹性伸缩。
HPortrait Controller
内置水平弹性伸缩算法管理组件,负责运行和管理针对不同工作负载的不同弹性伸缩算法的工作流,并将其输出结果转换为标准画像格式。具体的算法子任务则会作为单独的 Kubernetes Job 或者其他大数据/算法平台的任务被调度执行。这些子任务会从外部监控系统中获取历史与实时指标数据进行计算并生成画像结果。
特别的,部分简单算法(如响应式算法等)的逻辑是直接实现在该组件中,不再走单独的算法子任务。
Metrics Provider Server
统一监控指标查询组件,屏蔽底层监控系统差异,为外部运行的组件(如算法任务等)提供统一监控指标查询服务。
其提供的 API 与 Kubernetes Metrics API 类似,但不同的是它能够同时支持实时和历史指标查询。
Agent(暂未引入)
运行在 Kubernetes 集群节点上的 agent 组件,主要负责执行 Pod 的激保活等需要与底层操作系统进行交互的操作。
1.1.2 - 预测式扩缩容原理
预测式扩缩容的优势
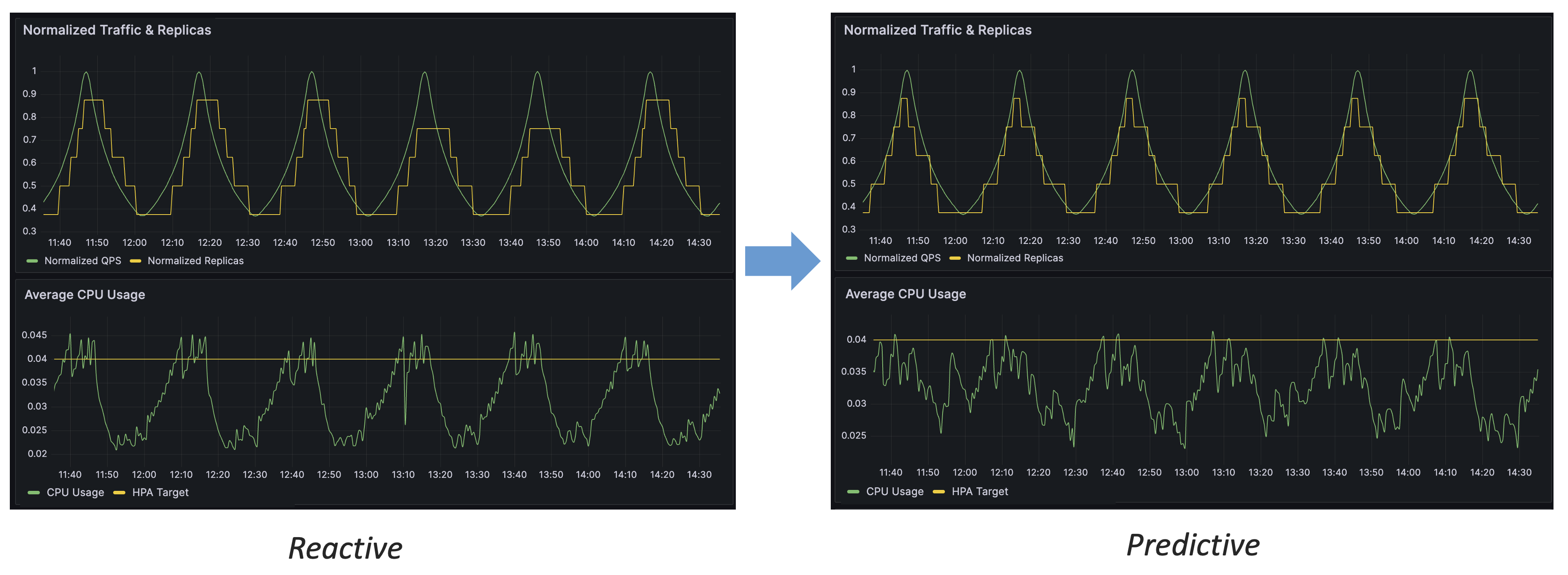
通过上图的对比,我们可以得出预测式扩缩容相比于响应式的几个优势:
- 预测式扩缩容能够提前对流量变化做出反应
- 预测式扩缩容能够更稳定地控制资源水位
- 预测式扩缩容具有更高的精度,能够更有效地利用资源
基于流量驱动的副本数预测
下面将详细介绍 IHPA 的「基于流量驱动的副本数预测」算法的设计思路与工作原理。
为什么要使用流量驱动
对于在线应用来说,容量(资源)指标(如 CPU 利用率)与流量是强相关的,即流量变化驱动了容量指标的变化。我们通过预测流量来评估容量,而非直接对容量指标进行预测,会有如下的好处:
- 流量指标是最上游的指标,先于容量指标发生变化,响应快
- 容量指标易受多种因素干扰(如应用自身的代码问题、宿主机性能等),而流量指标仅与应用特征直接相关(如用户的使用习惯),更易于进行时序预测
流量、容量与副本数关联建模
为了将副本数预测问题转化为流量预测问题,我们设计了一个 Linear-Residual Model 来找到流量、容量与副本数三者之间的关联函数,如下图所示:
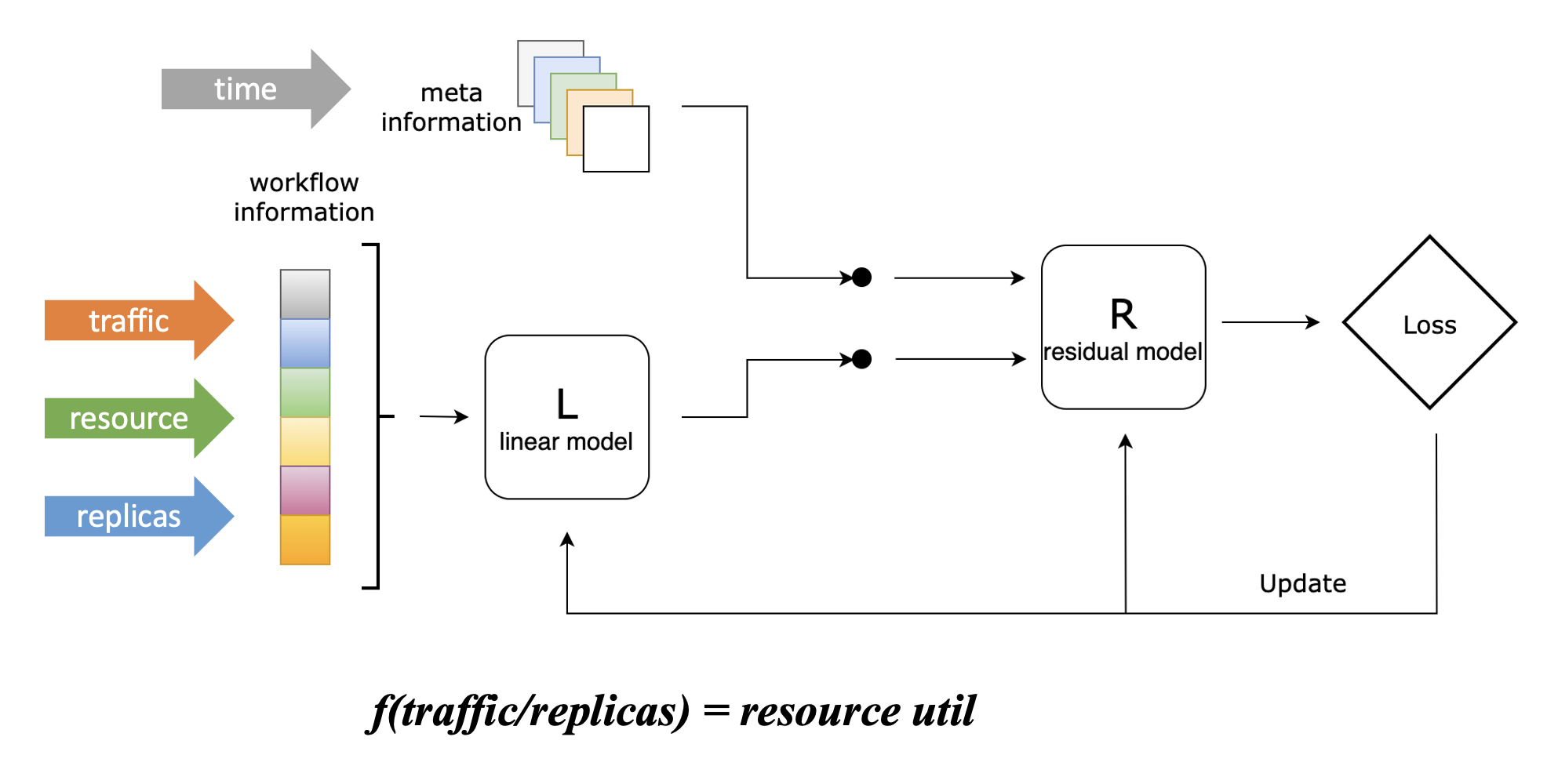
在该模型中,我们将资源利用率设置为目标指标,因为控制应用的资源水位是我们使用弹性伸缩的最终目的,这也是最符合直觉的。
但不同于 Kubernetes HPA 的响应式折比算法,虽然我们将资源利用率设置为目标指标,但该算法不会仅仅考虑资源利用率这一项指标,而是将历史流量(支持多条)、历史资源利用率、历史副本数都作为输入。这些指标会先通过一个线性模型,该模型能够学习这三者之间的线性关联,并得到上图中的关联函数;随后,它们会与其他信息一起(当前仅包含时间信息)通过一个残差模型,该将其他信息纳入考虑后对关联函数进行修正,能够学习到流量、容量和副本数之间的复杂非线性关联。
这里举一个简单的例子来说明残差模型的主要作用:假设某在线应用在每周日凌晨会执行一个内部定时任务,该任务会带来额外 CPU 资源消耗,但它与该应用处理的外部流量没有关联,这时候仅通过线性模型是无法学习到这一特征的。而引入残差模型后,该模型能够基于时间信息学习到该特征,因而在每周日凌晨的时间,我们给定与其他时间相同的流量和副本数,它所给出的函数会输出更高的 CPU 消耗,符合实际情况。
在目前的算法实现当中,我们使用了 ElasticNet 作为线性模型,LightGBM 作为残差模型,它们都是传统机器学习算法,不强依赖 GPU,相比于深度学习算法具有更低的使用开销,并且也能得到较好的效果。当然,你也可以根据自身的使用需求替换这些模型的具体实现,也欢迎提供你认为在某些场景下更优的实现。
在使用该模型得到关联函数之后,我们就能够把副本数预测问题转化为流量预测问题:已知目标资源利用率,只需要输入预测的流量,就能够得到(在预测流量下能够维持目标平均资源利用率的)预测的副本数。
模型细节
我们设工作流信息(包含流量、资源利用率、副本数信息)为 ,目标(资源利用率)值为 ,元信息(包括时间等)为 ,我们首先使用线性模型来描绘目标函数的骨架: 随后我们计算线性模型的误差: 之后,我们将该误差和元信息通过残差模型进行修正: 最后,我们能够得到 的估计值: 其中, 和 分别可以是任意的线性和残差模型。
流量时序预测
我们设计了一个名为 Swish Net for Time Series Forecasting 的深度学习模型来对流量指标进行时序预测,该模型专为 IHPA 的使用场景而优化,其具有下面两个主要特点:
- 轻量:该模型具有较简单的模型结构,这使得其具有较小的模型大小和较低的训练成本。以单条流量预测,12 个历史点预测 12 个未来点(在 10 分钟精度下即为 2 小时长度的预测)为例,其训练得到的模型大小小于 1 MiB;使用 PC 级 CPU 训练的情况下,一个 epoch 也只需要 1 分钟左右,约 1~2 小时就能训练完成。
- 在生产流量时序预测上的表现较好:我们使用生产流量数据集将该模型与其他常见深度学习时序预测模型进行了对比,可以看到该模型在生产流量时序预测任务上的表现优于其他模型,如下表所示:
| MAE | RMSE | |
|---|---|---|
| DeepAR | 1.734 | 31.315 |
| N-BEATS | 1.851 | 41.681 |
| ours | 1.597 | 28.732 |
模型细节
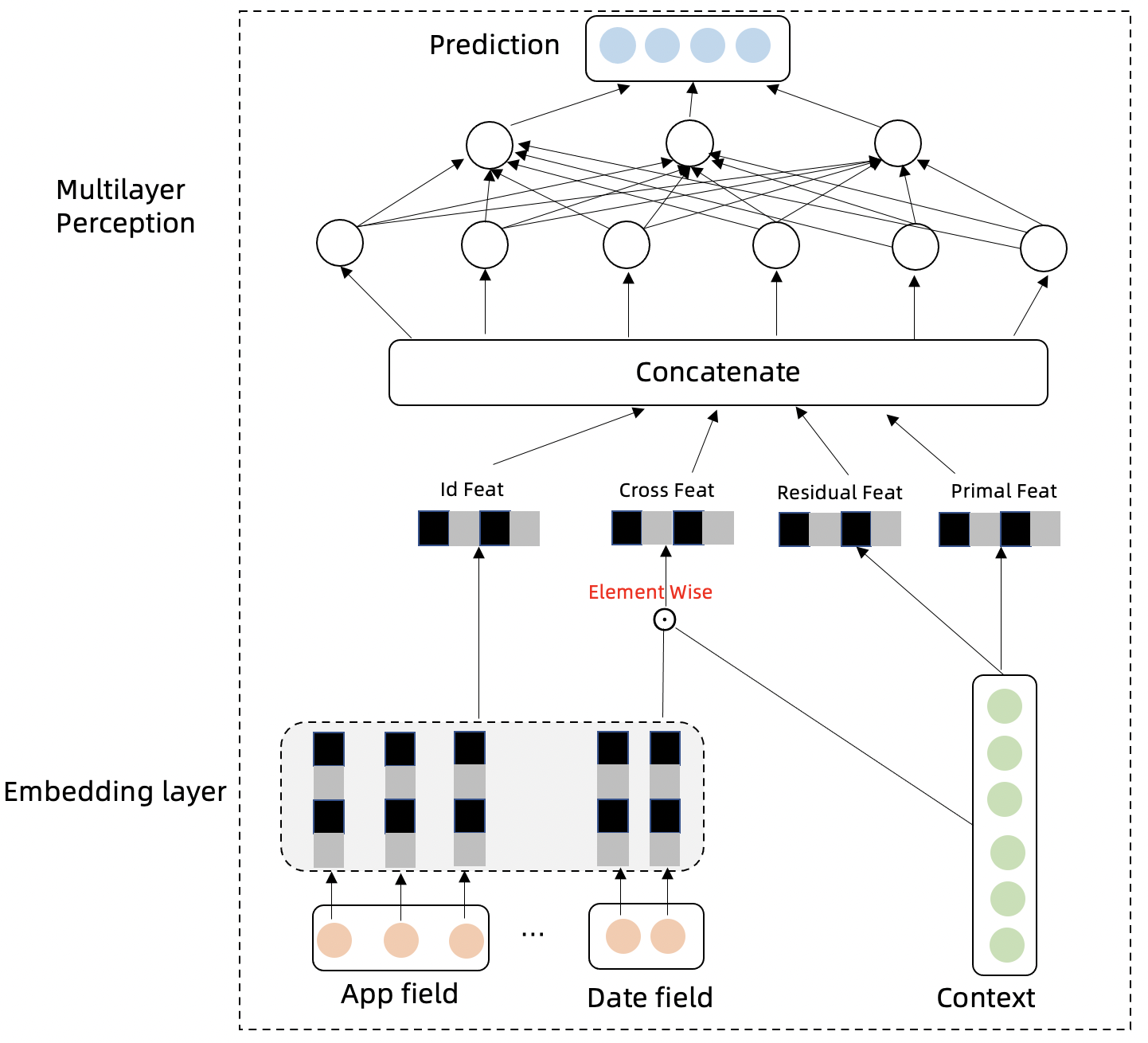
假设已经知道历史流量 ,未来真实流量为 ,预测流量为 ,流量所属的类别(如 App)为 。流量时间序列会存在周期性,趋势性,自回归特征,我们分别设计以下几个模块对这几种特性进行捕捉,并聚合信息对未来进行预测。
-
模型的 Embedding Layer 将类别信息和时间信息进行高维向量投射,类别信息表达不同序列的差异性,时间信息可以表达时间序列的周期性:
-
模型的时间特征和类别特征跟历史流量交叉特征点积可以进一步抽取不同序列的不同的差异性和周期性特征:
-
流量时间序列下一时间步骤与上一时间步骤的差分特征可以剔除趋势性,更好的表达时间序列的周期性,趋势性特征包含在原始序列中:
-
Multilayer Perception 层模型的输入以及网络结构表达如下: 多层时间网络对以上特征模块的信息进行汇总,并预测未来时间步的时间序列。
-
模型学习的损失函数为 MSE:
完整算法工作流
最后,我们将上述两个模型与相关数据源完整串接起来,就可以得到 IHPA 预测式扩缩容算法的完整工作流,如下图所示:
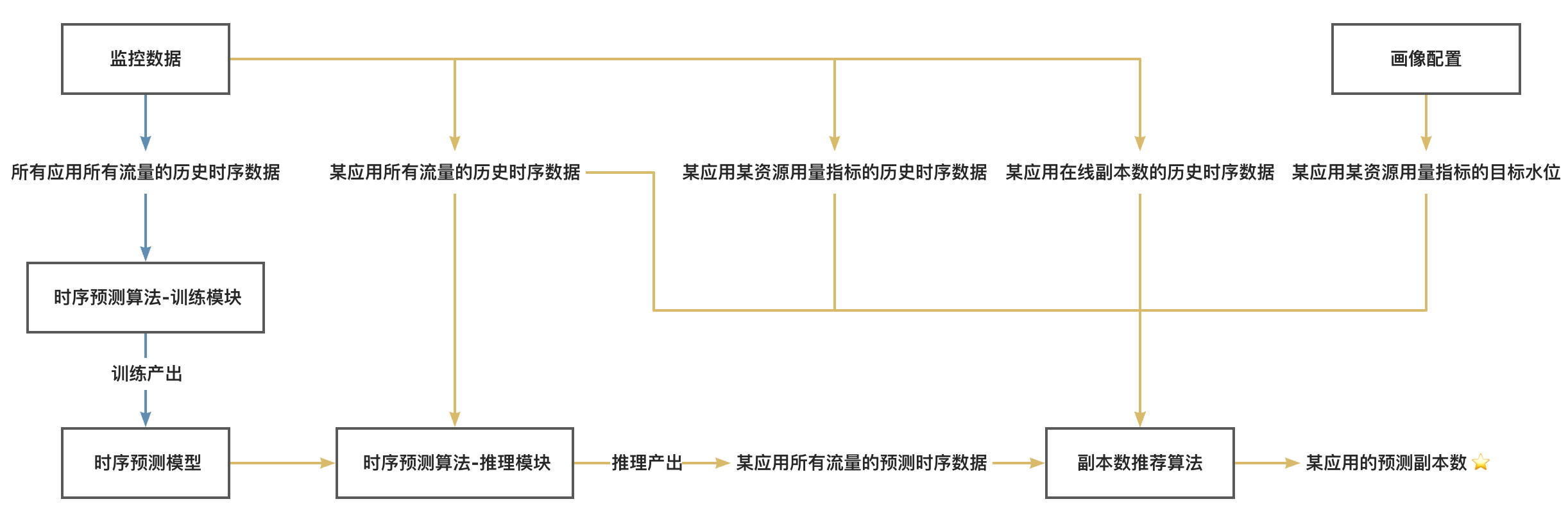
图例:
- 蓝色线为离线链路,需要较大量数据 & GPU & 较长的执行时间,执行频率较低
- 黄色线为在线链路,需要中等量数据 & CPU & 较短的执行时间,执行频率较高
注:
- 这里的「应用」是一个抽象概念,代表弹性伸缩的最小单元,通常是一个具体的工作负载如 Deployment 等
- 这里的「所有流量」并非代表监控系统中的所有可监控流量,而是代表与目标资源用量指标呈显著正相关的组分流量,可以根据具体应用场景按需选取
2 - 算法
2.1 - 训练时序预测模型
准备开始
本文档将指导您如何训练 Kapacity 所使用的时序预测深度学习算法的模型。
在开始之前,请确保您的环境已经安装了 Conda。
安装依赖
执行以下命令以下载你所使用的 Kapacity 算法版本的代码、安装算法依赖并激活算法运行环境:
git clone --depth 1 -b algorithm-<your-kapacity-algorithm-version> https://github.com/traas-stack/kapacity.git
cd kapacity/algorithm
conda env create -f environment.yml
conda activate kapacity
准备配置文件
训练脚本会从一个外部配置文件读取数据集拉取和模型训练的相关参数,因此我们需要提前准备好该配置文件。你可以下载这份示例配置文件 tsf-model-train-config.yaml 并按需修改其内容,该文件的内容如下所示:
targets:
- workloadNamespace: default
workloadRef:
apiVersion: apps/v1
kind: StatefulSet
name: nginx
historyLength: 24H
metrics:
- name: qps
type: Object
object:
metric:
name: nginx_ingress_controller_requests_rate
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: nginx-server
freq: 10min
predictionLength: 3
contextLength: 7
hyperParams:
learningRate: 0.001
epochs: 100
batchSize: 32
下面解释其中各字段的含义:
targets:待训练的工作负载及其指标信息列表(算法支持训练多个工作负载的多个指标到一个模型,但也会使模型变得更大),如果你希望手动准备数据集而非算法自动拉取,可不填写该字段。workloadNamespace:待训练工作负载所在命名空间。workloadRef:待训练工作负载对象的引用标识。historyLength:拉取作为数据集的指标历史长度,支持min(分钟)、H(小时)、D(天)三个时间单位。一般建议至少覆盖周期性指标的两个完整周期。metrics:该工作负载待训练的指标列表,格式同 IHPA 的指标字段。注意必须为每个指标设置不同的name以在同一个模型中的同一个工作负载下区分不同的指标。
freq:模型的精度,即下面predictionLength和contextLength参数的单位。目前支持的值为1min、10min、1H、1D。注意该参数不会影响模型大小。predictionLength:模型的预测点数,最终预测长度为predictionLength * freq。该参数设置地越大,模型也会越大。一般不建议设置得过大,因为预测的时间点越久远,预测的准确度也会越低。contextLength:模型在预测(推理)时参考的历史点数,最终参考的历史长度为contextLength * freq。该参数设置地越大,模型也会越大。hyperParams:深度学习模型的超参数,一般不需要调整。
训练模型
执行以下命令进行模型训练,注意将相关参数替换为真实值:
python kapacity/timeseries/forecasting/train.py \
--config-file=<your-config-file> \
--model-save-path=<your-model-save-path> \
--dataset-file=<your-datset-file> \
--metrics-server-addr=<your-metrics-server-addr> \
--dataloader-num-workers=<your-dataloader-num-workers>
下面解释各参数的含义:
config-file:上一步准备的配置文件的地址。model-save-path:模型要保存到的目录地址。dataset-file:手动准备的数据集文件的地址。和metrics-server-addr参数二选一填写。metrics-server-addr:用于自动拉取数据集的指标服务器的地址,即可访问的 Kapacity gRPC 服务的地址。和dataset-file参数二选一填写。dataloader-num-workers:用于加载数据集的子进程数量,一般建议设置为本机 CPU 核数,如果设置为0则仅使用主进程加载。
关于如何访问 Kapacity gRPC 服务的贴士
默认情况下,Kapacity 的 gRPC 服务会暴露为一个 ClusterIP Service,你可以使用如下命令查看其 ClusterIP 和端口:
kubectl get svc -n kapacity-system kapacity-grpc-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kapacity-grpc-service ClusterIP 192.168.38.172 <none> 9090/TCP 5m
如果你是在集群中运行训练脚本,则可以直接使用该 ClusterIP 和端口作为 metrics-server-addr。
如果你不在集群中运行训练脚本,则可以使用如下命令通过 kubectl 的端口转发功能来从本机访问集群中的这个 Service,注意将 <local-port> 替换为本地的一个闲置端口:
kubectl port-forward -n kapacity-system svc/kapacity-grpc-service <local-port>:9090
随后,你可以使用 localhost:<local-port> 作为 metrics-server-addr。
执行后你将看到类似下面内容的训练日志,请等待直到训练完成(命令正常退出):
2023-10-18 20:05:07,757 - INFO: Epoch: 1 cost time: 55.25944399833679
2023-10-18 20:05:07,774 - INFO: Epoch: 1, Steps: 6 | Train Loss: 188888896.6564227
Validation loss decreased (inf --> 188888896.656423). Saving model ...
2023-10-18 20:05:51,157 - INFO: Epoch: 2 cost time: 43.38192820549011
2023-10-18 20:05:51,158 - INFO: Epoch: 2, Steps: 6 | Train Loss: 212027786.7585510
EarlyStopping counter: 1 out of 15
2023-10-18 20:06:30,055 - INFO: Epoch: 3 cost time: 38.89493203163147
2023-10-18 20:06:30,060 - INFO: Epoch: 3, Steps: 6 | Train Loss: 226666666.7703293
训练完成后你可以在 model-save-path 目录下看到训练好的模型及其附属文件:
-rw-r--r-- 1 admin staff 316K Oct 18 20:18 checkpoint.pth
-rw-r--r-- 1 admin staff 287B Oct 18 20:04 estimator_config.yaml
-rw-r--r-- 1 admin staff 29B Oct 18 20:04 item2id.json
3 - 使用自定义指标
背景
Kubernetes Metrics API 提供了一套 K8s 体系内的通用指标查询接口,但它只支持查询指标的当前实时值,而不支持查询历史值,此外,它也不支持基于工作负载维度的 Pod 指标聚合查询,无法满足各类智能算法的数据需求。因此,Kapacity 对 Metrics API 进行了进一步的抽象和扩展,在最大程度兼容用户使用习惯的同时支持了通用的指标历史查询与工作负载维度聚合查询等高阶查询能力。
目前,Kapacity 提供的 Metrics API 支持下面两种指标查询后端:
使用 Prometheus 作为指标查询后端(默认)
将 Kapacity Manager 的启动参数 --metric-provider 设置为 prometheus 以使用 Prometheus 作为指标查询后端。
如果使用此后端,你只需要有一个 Prometheus,无需安装 Kubernetes Metrics Server 或其他 Metrics Adapter(包括 Prometheus Adapter)。
你可以在 Kapacity Manager 所在命名空间的 ConfigMap kapacity-config 中找到 prometheus-metrics-config.yaml 这份配置,通过修改这份配置,你可以完全自定义不同指标类型的 Prometheus 查询语句。这份配置的格式完全兼容 Prometheus Adapter 的配置,因此,如果你此前使用 Prometheus Adapter 配置了自定义 HPA 指标,可以直接复用以前的配置。
当前 Kapacity 提供的默认配置如下所示:
resourceRules:
cpu:
containerQuery: |-
sum by (<<.GroupBy>>) (
irate(container_cpu_usage_seconds_total{container!="",container!="POD",<<.LabelMatchers>>}[3m])
)
readyPodsOnlyContainerQuery: |-
sum by (<<.GroupBy>>) (
(kube_pod_status_ready{condition="true"} == 1)
* on (namespace, pod) group_left ()
sum by (namespace, pod) (
irate(container_cpu_usage_seconds_total{container!="",container!="POD",<<.LabelMatchers>>}[3m])
)
)
resources:
overrides:
namespace:
resource: namespace
pod:
resource: pod
containerLabel: container
memory:
containerQuery: |-
sum by (<<.GroupBy>>) (
container_memory_working_set_bytes{container!="",container!="POD",<<.LabelMatchers>>}
)
readyPodsOnlyContainerQuery: |-
sum by (<<.GroupBy>>) (
(kube_pod_status_ready{condition="true"} == 1)
* on (namespace, pod) group_left ()
sum by (namespace, pod) (
container_memory_working_set_bytes{container!="",container!="POD",<<.LabelMatchers>>}
)
)
resources:
overrides:
namespace:
resource: namespace
pod:
resource: pod
containerLabel: container
window: 3m
rules: []
externalRules:
- seriesQuery: '{__name__="kube_pod_status_ready"}'
metricsQuery: sum(<<.Series>>{condition="true",<<.LabelMatchers>>})
name:
as: ready_pods_count
resources:
overrides:
namespace:
resource: namespace
workloadPodNamePatterns:
- group: apps
kind: ReplicaSet
pattern: ^%s-[a-z0-9]+$
- group: apps
kind: Deployment
pattern: ^%s-[a-z0-9]+-[a-z0-9]+$
- group: apps
kind: StatefulSet
pattern: ^%s-[0-9]+$
为了支持工作负载维度聚合查询等高阶查询能力,我们在 Prometheus Adapter 配置之上扩展了部分字段,下面对这些扩展字段作简要说明:
workloadPodNamePatterns:Kapacity 的部分算法会需要查询工作负载维度的指标信息,如某工作负载 Pods 的 CPU 总用量、某工作负载的 Ready Pods 数量等,此时 Kapacity 会以工作负载 Pod 名称正则匹配的方式对 Pod 维度的指标做聚合查询,因此需要通过该字段配置不同类型工作负载的 Pod 名称正则匹配规则。如果你使用了默认配置以外的其他工作负载,需要在该字段中添加相应配置。readyPodsOnlyContainerQuery:Kapacity 的部分算法在查询工作负载 Pods 的资源总用量时会有额外的条件,如仅查询某工作负载 Ready Pods 的 CPU 总用量,此时我们需要使用该字段提供一条单独的 PQL 语句来做此特殊条件下的查询。Kapacity 默认提供了基于 kube-state-metrics 所提供指标的查询语句,你也可以按需修改为其他实现。
使用 Kubernetes Metrics API 作为指标查询后端(不推荐)
将 Kapacity Manager 的启动参数 --metric-provider 设置为 metrics-api 以使用 Kubernetes Metrics API 作为指标查询后端。
如果使用此后端,你需要安装 Kubernetes Metrics Server 或其他 Metrics Adapter(如 Prometheus Adapter),由它们来屏蔽下层监控系统差异。
但需要注意的是,此后端不支持指标历史值查询,也不支持基于工作负载维度的 Pod 指标聚合查询,因此其可用范围非常有限,只适用于部分仅使用简单算法的场景,如响应式扩缩容。
4 - 常见问题
IHPA
预测式算法任务执行报错 replicas estimation failed
该报错是由于「流量、容量与副本数关联建模」算法没有产出可用的模型导致,可以尝试下面的方法解决此问题:
- 通过调整算法任务参数
--re-history-len增大历史数据长度。 - 结合报错返回的详细模型评估信息,通过调整算法任务参数
--re-min-correlation-allowed与--re-max-mse-allowed适当放宽模型的验证要求。但需要注意,如果放宽的值和默认值差距过大,模型的准确性将很难得到保证。