Introduction
6 minute read
Kapacity is an open cloud native capacity solution which helps you achieve ultimate resource utilization in an intelligent and risk-free way.
It automates your scaling, mitigates capacity risks, saves your effort as well as cost.
Kapacity is built upon core ideas and years of experience of the large-scale production capacity system at Ant Group, which saves ~100k cores yearly with high stability and zero downtime, combined with best practices from the cloud native community.
Watch our talk (in Chinese) at KubeCon China 2023 “How We Build Production-Grade HPA: From Effective Algorithm to Risk-Free Autoscaling” to learn the core idea and principles of Kapacity’s Intelligent HPA in depth!
Core Features
Intelligent HPA
Kubernetes HPA is a common way used to scale cloud native workloads automatically, but it has some BIG limitations listed below which make it less effective and practical in real world large-scale production use:
- HPA works in a reactive way, which means it would only work AFTER the target metrics exceeding the expected value. It can hardly provide rapid and graceful response to traffic peaks, especially for applications with longer startup times.
- HPA calculates replica count based on metrics by a simple ratio algorithm, with an assumption that the replica count must have a strict linear correlation with related metrics. However, this is not always the case in real world.
- Scaling is a highly risky operation in production, but HPA provides little risk mitigation means other than scaling rate control.
- HPA is a Kubernetes built-in, well, this is not a limitation literally, but it does limit some functions/behaviors to specific Kubernetes versions, and there is no way for end users to extend or adjust its functionality for their own needs.
So we build Intelligent HPA (IHPA), an intelligent, risk-defensive, highly adaptive and customizable substitution for HPA. It has following core features:
Intelligent Scaling
Autoscaling is essentially a data-driven decision-making process. IHPA can make use of different algorithms under different scenarios. In addition to simple cron-based replica control and classic reactive ratio algorithms, it also supports a variety of intelligent algorithms such as predictive and burst algorithms, and all these algorithms can be combined to take effect based on custom strategies which enables IHPA to adapt to a wide variety of use cases.
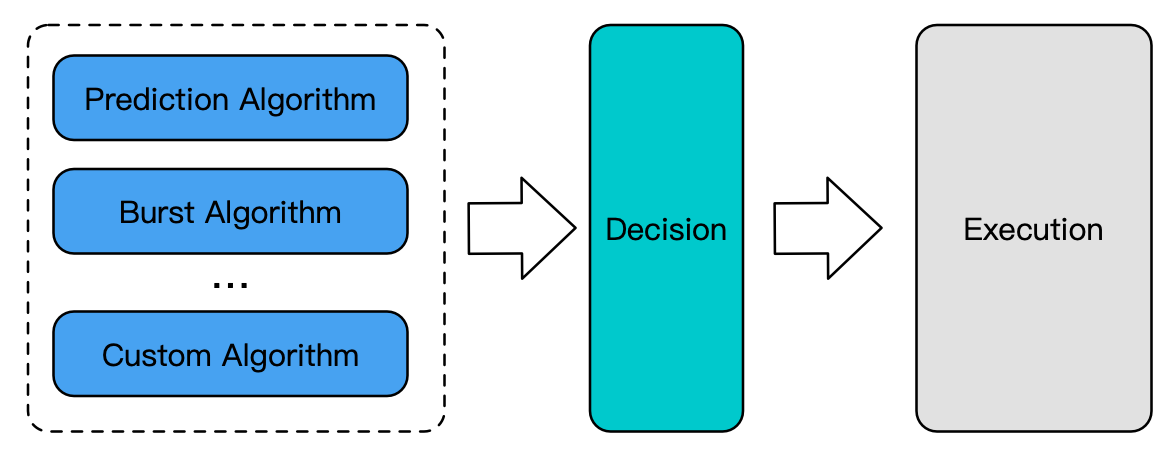
Taking the predictive algorithm as an example, in real world production, the resource utilization of an application is usually affected by multiple external traffics, or even its own tasks, machine performance, etc., and the relationship between replicas and resource utilization might not be linear. This presents a great challenge to replicas prediction.
To solve this problem, IHPA introduces a set of predictive algorithms based on machine learning that Ant Group has adopt to its internal large-scale production workloads. It first does time series prediction (making use of Swish Net for Time Series Forecasting, which is optimized for traffic forcasting) for each application traffic, and then uses the Linear-Residual Model to build a comprehensive relationship between traffics, resource utilization and replicas, and finally makes use of the relationship and traffic predictions to infer the recommended future replicas for the application.
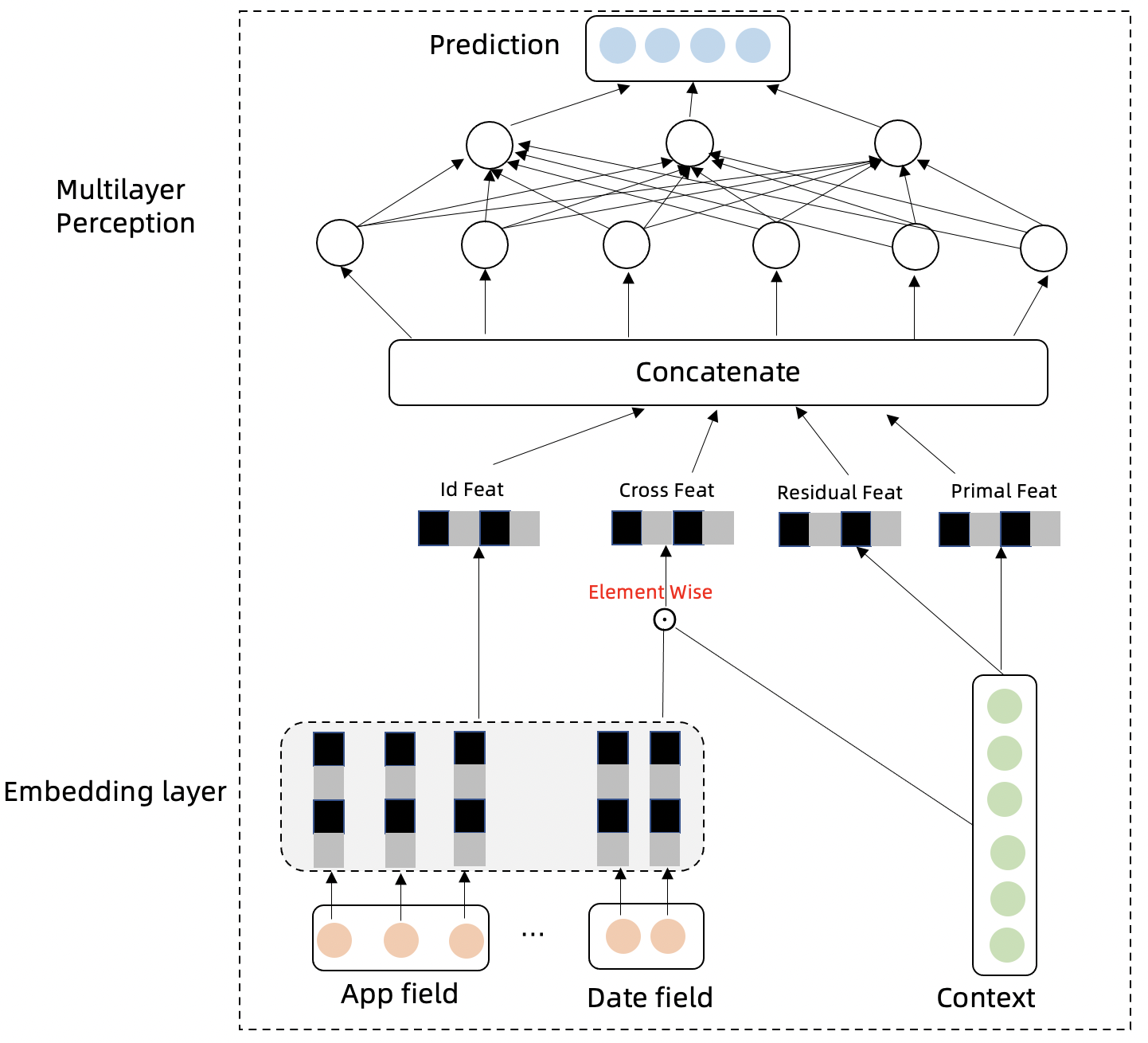
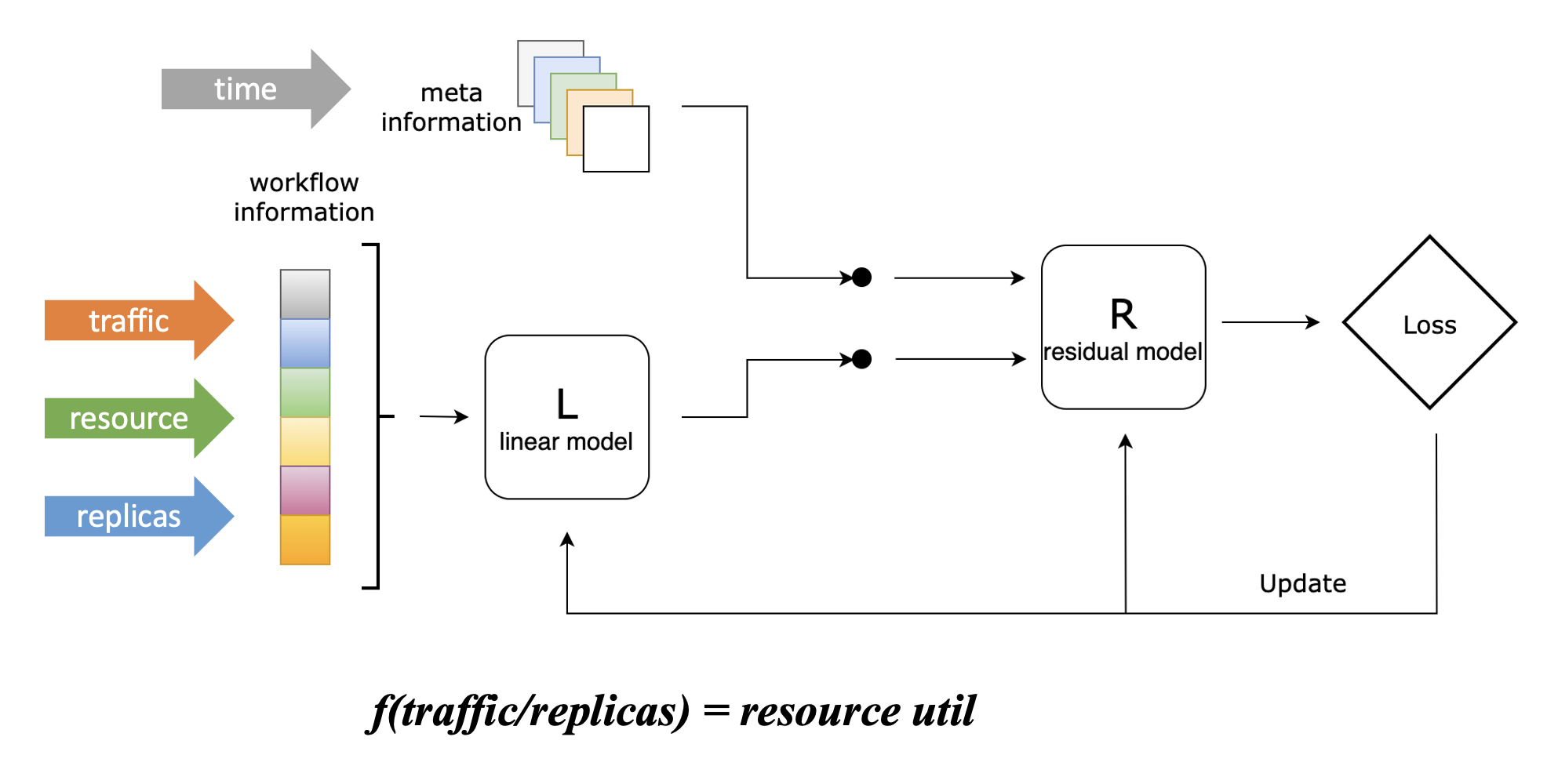
Through the core “traffic-driven” idea, this algorithm is suitable for a variety of complex scenarios in real-world production such as multi period and trending traffic, load affected by multiple traffics, non-linear correlation between load and replica count, and so on.
Multi-Stage Scaling
Unlike Kubernetes HPA which only supports simply scaling workloads up and down, IHPA supports fine-grained control of the state of each Pod under the workload throughout the scaling process, which improves the scaling efficiency as well as mitigates scaling risks.
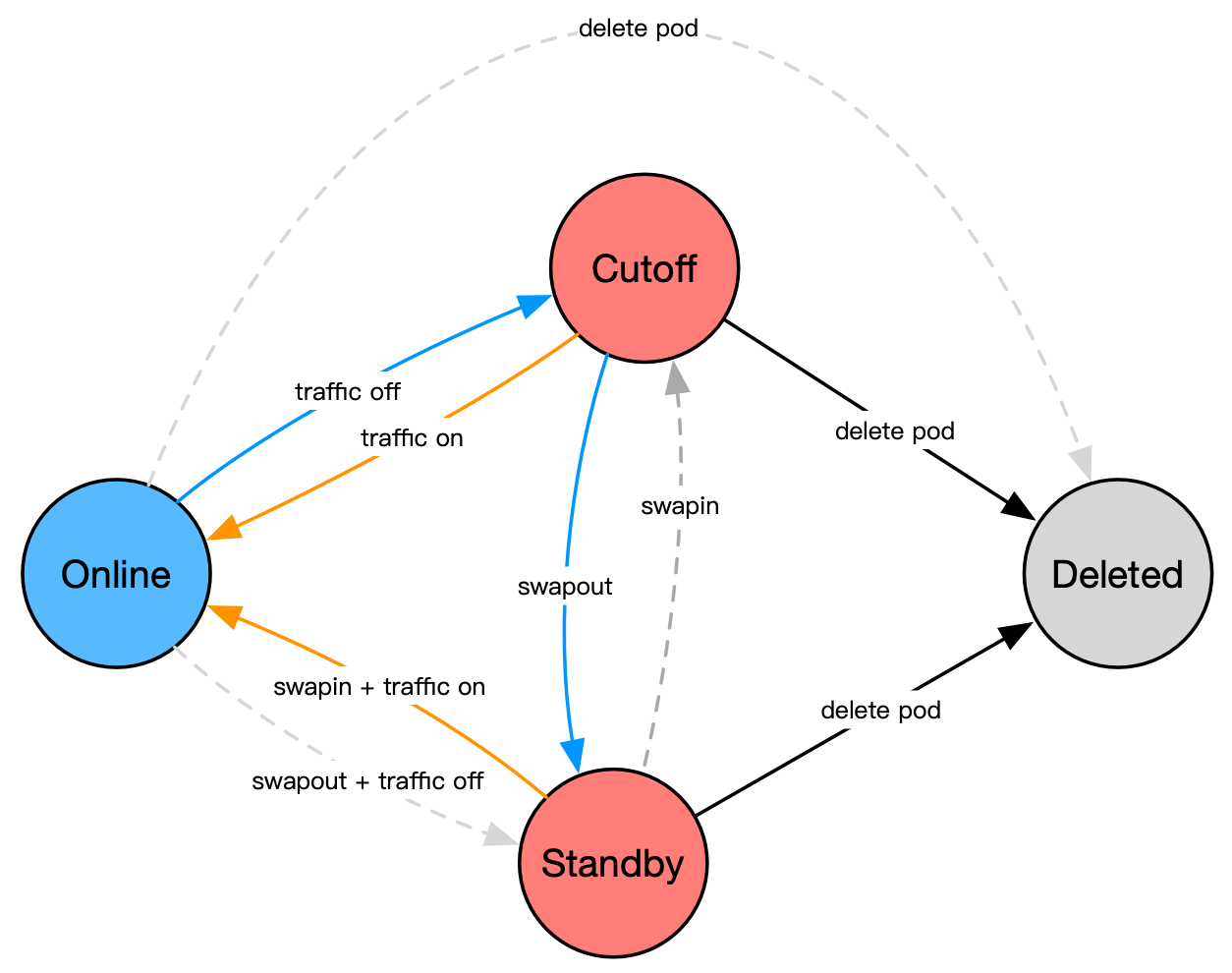
Kapacity defines the following Pod states currently:
- Online: The Pod is serving traffics normally (Running and Ready). It is also the default state of every newly created Pod.
- Cutoff: The Pod is running but not serving traffics (Running but Not Ready). In practice, IHPA supports scaling down Pod to this state with additional stability observation time, and once a risk is detected, the Pod can be rolled back to the Online state in seconds.
- Standby: The Pod’s resources are swapped out and kept at a low usage level. Compared with the Cutoff state, this state can actually release the resources of the Pod for reuse, and also supports rolling back to the Online state in minutes.
- Deleted: The Pod has been deleted. In fact, the Pod itself would not exist in this state.
High Stability
IHPA is built upon years of experience of autoscaling practice for large-scale production workloads at Ant Group, which leads to many unique abilities to guarantee high stability during autoscaling.
Gray Scaling
IHPA supports fully customizable gray change for both scale up and scale down, and it can even be combined with the pod state control mechanism to achieve multi-stage gray change.
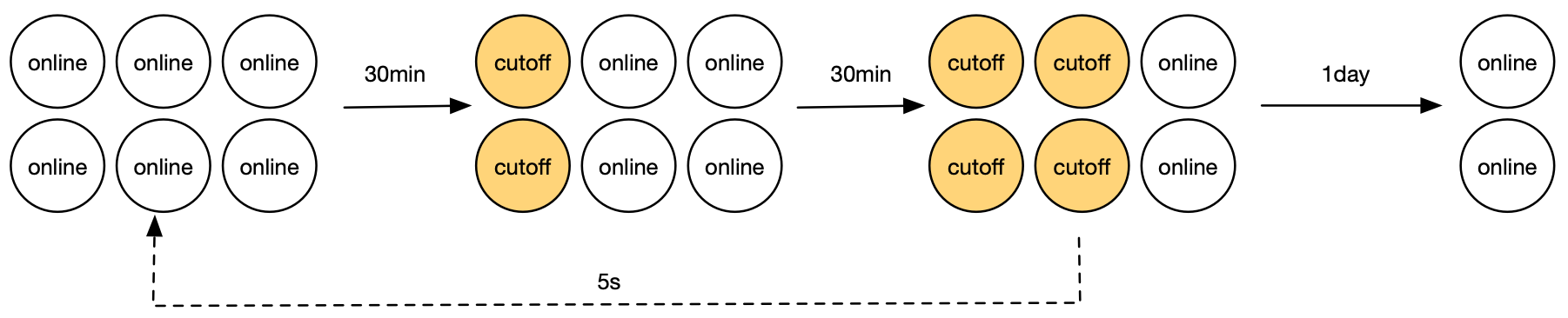
The following example shows the process of a multi-stage gray scaling: At first, the workload has 6 Pods, and IHPA wants to scale it down to 2 Pods. Then IHPA would change the Pods’ state in batch according to user’s configurations. Users (or IHPA itself, introduced in next section) can do stability observation between each change. In addition, there would be an additional observation period at the end of gray change. If everything work smoothly, the Pods would be actually scaled down at the end of the observation period. Or if any risk is detected, the Pods can be rolled back to the Online state very quickly.
Automatic Risk Detection and Mitigation
Sometimes it is not easy to detect risks only by monitoring the metrics used for scaling during autoscaling. Therefore, IHPA supports automatic risk mitigation based on customizable stability checks. You can let it monitor arbitrary metrics (not limited to the metrics which drive autoscaling) for risk detection, or even define your own detection logic, and it can automatically take actions such as suspend or rollback the scaling to mitigate risks, which achieves a fully automated autoscaling with high stability.
Open and Highly Extensible Architecture
Kapacity is born to be an open project which is easy to integrate or extend. For IHPA as an example:
- IHPA is split into three independent modules for replica count calculation, workload replicas control and overall autoscaling process management. Each module is replaceable and extensible.
- Various extension points are exposed which makes the behavior of IHPA fully customizable and extensible. For example, you can customize how to control traffics of the pod, which pods shall be scaled down first, how to detect risks during autoscaling and so on.