This is the multi-page printable view of this section. Click here to print.
Quick Start
- 1: IHPA (Intelligent HPA)
- 1.1: Cron Scaling
- 1.2: Reactive Scaling
- 1.3: Predictive Scaling
- 1.4: Multi-Stage Gray Scaling
1 - IHPA (Intelligent HPA)
IHPA (Intelligent HPA) is an intelligent, risk-defensive, highly adaptive and customizable substitution for HPA.
You can follow below guides to quickly try some core features of IHPA.
1.1 - Cron Scaling
Before you begin
You need to have a Kubernetes cluster with Kapacity installed.
Run sample workload
Download nginx-statefulset.yaml and run following command to run an NGINX workload:
kubectl apply -f nginx-statefulset.yaml
Check if the workload is running:
kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-0 1/1 Running 0 5s
Create IHPA with cron portrait provider
Download cron-portrait-sample.yaml which looks like this:
apiVersion: autoscaling.kapacitystack.io/v1alpha1
kind: IntelligentHorizontalPodAutoscaler
metadata:
name: cron-portrait-sample
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: nginx
minReplicas: 1
maxReplicas: 10
portraitProviders:
- type: Cron
priority: 1
cron:
crons:
- name: cron-1
start: 0 * * * *
end: 10 * * * *
replicas: 1
- name: cron-2
start: 10 * * * *
end: 20 * * * *
replicas: 2
- name: cron-3
start: 20 * * * *
end: 30 * * * *
replicas: 3
- name: cron-4
start: 30 * * * *
end: 40 * * * *
replicas: 4
- name: cron-5
start: 40 * * * *
end: 50 * * * *
replicas: 5
Run following command to create the IHPA:
kubectl apply -f cron-portrait-sample.yaml
Verify results
You can see that the replica number of the workload is changing dynamically accroding to our configration by checking the events of the IHPA:
kubectl describe ihpa cron-portrait-sample
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CreateReplicaProfile 38m ihpa_controller create ReplicaProfile with onlineReplcas: 3, cutoffReplicas: 0, standbyReplicas: 0
Normal UpdateReplicaProfile 33m (x2 over 33m) ihpa_controller update ReplicaProfile with onlineReplcas: 3 -> 4, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 23m ihpa_controller update ReplicaProfile with onlineReplcas: 4 -> 5, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Warning NoValidPortraitValue 13m ihpa_controller no valid portrait value for now
Normal UpdateReplicaProfile 3m15s ihpa_controller update ReplicaProfile with onlineReplcas: 5 -> 1, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
You can also verify it by directly watching the replica number of the workload.
Note
You can see aNoValidPortraitValue event because the cron expressions configured do not cover this period of time, and the replica number of the workload will remain unchanged at this time.
Cleanup
Run following command to cleanup all the resources:
kubectl delete -f cron-portrait-sample.yaml
kubectl delete -f nginx-statefulset.yaml
1.2 - Reactive Scaling
Before you begin
You need to have a Kubernetes cluster with Kapacity and Prometheus installed.
Run sample workload
Download nginx-statefulset.yaml and run following command to run an NGINX workload:
kubectl apply -f nginx-statefulset.yaml
Check if the workload is running:
kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-0 1/1 Running 0 5s
Create IHPA with dynamic reactive portrait provider
Download dynamic-reactive-portrait-sample.yaml which looks like this:
apiVersion: autoscaling.kapacitystack.io/v1alpha1
kind: IntelligentHorizontalPodAutoscaler
metadata:
name: dynamic-reactive-portrait-sample
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: nginx
minReplicas: 1
maxReplicas: 10
portraitProviders:
- type: Dynamic
priority: 1
dynamic:
portraitType: Reactive
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 30
algorithm:
type: KubeHPA
Run following command to create the IHPA:
kubectl apply -f dynamic-reactive-portrait-sample.yaml
Increase the load
Run following command to get the ClusterIP and port of the NGINX service:
kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP 10.111.21.74 <none> 80/TCP 13m
Start a different pod to act as a client which will send requests to the NGINX service infinitely with the service ip and port replaced by the value got in previous step:
# Run this in a separate terminal so that the load generation continues and you can carry on with the rest of the steps
kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://<service-ip>:<service-port> > /dev/null; done"
After several minutes, you can see that the workload is scaled up by checking events of the IHPA:
kubectl describe ihpa dynamic-reactive-portrait-sample
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CreateReplicaProfile 6m58s ihpa_controller create ReplicaProfile with onlineReplcas: 1, cutoffReplicas: 0, standbyReplicas: 0
Normal UpdateReplicaProfile 3m45s ihpa_controller update ReplicaProfile with onlineReplcas: 1 -> 6, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Stop generating load
In the terminal where you created the Pod that runs a busybox image, terminate the load generation by typing <Ctrl> + C.
After several minutes, you can see that the workload is scaled down by checking events of the IHPA:
kubectl describe ihpa dynamic-reactive-portrait-sample
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CreateReplicaProfile 9m58s ihpa_controller create ReplicaProfile with onlineReplcas: 1, cutoffReplicas: 0, standbyReplicas: 0
Normal UpdateReplicaProfile 6m45s ihpa_controller update ReplicaProfile with onlineReplcas: 1 -> 6, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 3m15s ihpa_controller update ReplicaProfile with onlineReplcas: 6 -> 4, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 2m45s ihpa_controller update ReplicaProfile with onlineReplcas: 4 -> 1, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Cleanup
Run following command to cleanup all the resources:
kubectl delete -f dynamic-reactive-portrait-sample.yaml
kubectl delete -f nginx-statefulset.yaml
1.3 - Predictive Scaling
Note: Most contents of this page are translated by AI from Chinese. It would be very appreciated if you could help us improve by editing this page (click the corresponding link on the right side).
Before you begin
You need to have a Kubernetes cluster with Kapacity and Prometheus installed.
Make sure your Kubernetes cluster has a working DNS (like CoreDNS) to resolve Service domain names. If not, you need to adjust the configuration of Kapacity as follows:
Use the following command to view the ClusterIP and port of the Kapacity gRPC Server:
kubectl get svc -n kapacity-system kapacity-grpc-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kapacity-grpc-service ClusterIP 192.168.38.172 <none> 9090/TCP 5m
Use the following command to update the configuration of Kapacity, where the parameters related to the Kapacity gRPC Server address are the values viewed in the previous step:
helm upgrade \
kapacity-manager kapacity/kapacity-manager \
--namespace kapacity-system \
--reuse-values \
--set algorithmJob.defaultMetricsServerAddr=<kapacity-grpc-server-clusterip>:<kapacity-grpc-server-port>
Install and configure Ingress NGINX Controller
Kapacity IHPA’s predictive scaling uses the “Traffic-Driven Replicas Prediction” algorithm, so we need at least one traffic metric to use predictive scaling. Here we use Ingress NGINX as an example of workload ingress traffic.
If your Kubernetes cluster does not yet have Ingress NGINX Controller, please refer to the official documentation for installation.
After the installation is complete, follow this document to configure to ensure that Prometheus can collect the metrics of Ingress NGINX.
Configure Kapacity to recognize Ingress NGINX metrics
Use the following command to add the metrics of Ingress NGINX in the custom Prometheus metrics configuration of Kapacity:
kubectl edit cm -n kapacity-system kapacity-config
apiVersion: v1
data:
prometheus-metrics-config.yaml: |
resourceRules:
...
# add Ingress NGINX metrics in rules
rules:
- seriesQuery: '{__name__="nginx_ingress_controller_requests"}'
metricsQuery: round(sum(irate(<<.Series>>{<<.LabelMatchers>>}[3m])) by (<<.GroupBy>>), 0.001)
name:
as: nginx_ingress_controller_requests_rate
resources:
template: <<.Resource>>
# note: uncomment the overrides field below if your Prometheus is installed with Prometheus Operator
# overrides:
# exported_namespace:
# resource: namespace
externalRules:
...
kind: ConfigMap
...
As you can see, this configuration is fully compatible with the Prometheus Adapter configuration, more background information can be found in this user guide.
Then, use the following command to restart Kapacity Manager to load the latest configuration:
kubectl rollout restart -n kapacity-system deploy/kapacity-manager
Notice
Kapacity Manager requires some time to sync the custom metric configuration from Prometheus after startup. If there are many metrics within Prometheus, it might take a considerable amount of time (usually several minutes). You can determine whether the synchronization is complete by checking the standard output logs of the Kapacity Manager Pod for the messagemetrics relisted successfully. Please wait for Kapacity Manager to finish synchronizing the custom metrics before proceeding with subsequent steps.
Run sample workload
- Download nginx-statefulset.yaml and run following command to run an NGINX workload:
kubectl apply -f nginx-statefulset.yaml
Check if the workload is running:
kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-0 1/1 Running 0 5s
- Download nginx-ingress.yaml and run following command to create an Ingress for the NGINX workload:
kubectl apply -f nginx-ingress.yaml
Verify that Ingress was created successfully and record the ADDRESS of Ingress:
kubectl get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
nginx-server nginx nginx.example.com 139.224.120.211 80 2d
- Download periodic-client.yaml,replace
<nginx-ingress-address>with the ADDRESS of the Ingress recorded in the previous step, and then execute the following command to create a client Pod that sends requests to the NGINX service on a periodic basis (with 1 hour as 1 cycle):
kubectl apply -f periodic-client.yaml
It will generate periodic traffic as shown in the following figure:
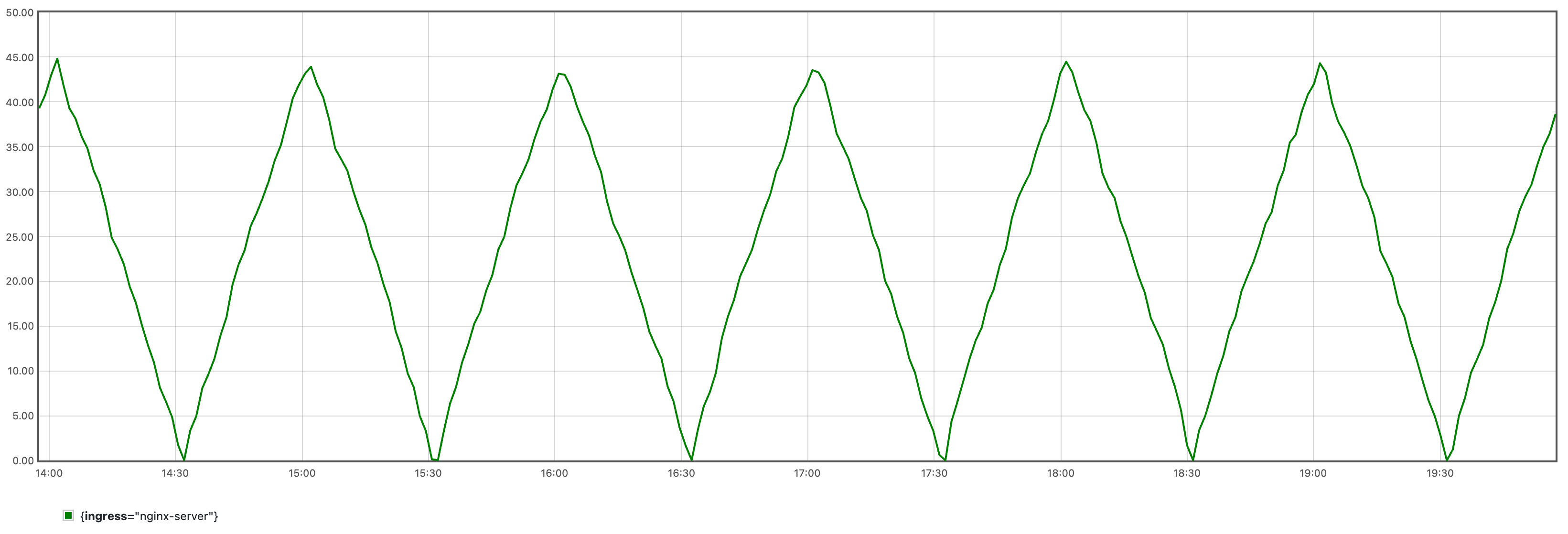
Since the algorithm needs a certain amount of data for learning, it is recommended to run for at least 24 hours before proceeding to the next step.
Train time series forecasting model
Please refer to the user guide to use this configuration to complete the training of the time series prediction model, and then execute the following command to save the model and its accessory files as a ConfigMap for subsequent algorithm tasks to use, replace <model-save-path> with the actual model saving directory path:
kubectl create cm -n kapacity-system example-model --from-file=<model-save-path>
Note
In actual use, we may get a larger model, in this case, we recommend storing model files on persistent volumes rather than a ConfigMap.Create IHPA with dynamic predictive portrait provider
Download dynamic-predictive-portrait-sample.yaml which looks like this:
apiVersion: autoscaling.kapacitystack.io/v1alpha1
kind: IntelligentHorizontalPodAutoscaler
metadata:
name: predictive-sample
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: nginx
minReplicas: 1
maxReplicas: 10
portraitProviders:
- type: Dynamic
priority: 1
dynamic:
portraitType: Predictive
metrics:
- type: Resource
resource:
name: cpu
target:
type: AverageValue
averageValue: 1m
- type: Pods
pods:
metric:
name: kube_pod_status_ready
target:
type: NA
- name: qps
type: Object
object:
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: nginx-server
metric:
name: nginx_ingress_controller_requests_rate
target:
type: NA
algorithm:
type: ExternalJob
externalJob:
job:
type: CronJob
cronJob:
template:
spec:
schedule: "0/30 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: algorithm
args:
- --tsf-model-path=/opt/kapacity/timeseries/forecasting/model
- --re-history-len=24H
- --re-time-delta-hours=8
- --re-test-dataset-size-in-seconds=3600
- --scaling-freq=10min
volumeMounts:
- name: model
mountPath: /opt/kapacity/timeseries/forecasting/model
readOnly: true
volumes:
- name: model
configMap:
name: example-model
restartPolicy: OnFailure
resultSource:
type: ConfigMap
Please replace the value of the algorithm parameter --re-time-delta-hours with the UTC offset value of your time zone, such as 8 for UTC+8 time zone, -7 for UTC-7 time zone.
Let’s look at the metrics first. In the “Traffic-driven replica prediction” algorithm, we need multiple types of metrics to jointly drive the algorithm, so we have agreed on the following metric configuration specification:
- The first metric should be configured as the target resource metric of this workload, so the type can only be
ResourceorContainerResource. It specifies the target resource level we expect IHPA to help us maintain. - The second metric should be configured as the online replica count metric of this workload. The algorithm will use this metric to query the historical Ready Pod (i.e., the Pod carrying traffic) count of this workload. The type of this metric can only be
Pods. It will be aggregated on the workload dimension by regular matching of the Pod name for the query. Kapacity defaults to thekube_pod_status_readymetric based on kube-state-metrics for direct use. Note that since this metric is only used for historical query, we do not need to specify a target value for it. Therefore, we write a placeholderNAfor itstargettype. - The third and subsequent metrics should be configured as traffic metrics (such as QPS, RPC, etc.) that are positively correlated with the target resource metric of this workload. The algorithm will perform time series prediction on these metrics, and then based on the historical resource level and replica count, it will give a predicted replica count that can meet the target resource level in the future. These metrics can be of any type other than
ResourceandContainerResource, but note that you must set the samenamefor these metrics as set during training. Similarly, these metrics are also only used for historical queries, so you do not need to set target values.
Then let’s look at the algorithm parameters. Here is a brief explanation of the functions of a few key parameters. More information can be referred to the flags description of the algorithm script itself:
--re-history-len: This parameter specifies the historical length of the replica recommendation algorithm learning, it is generally recommended to cover at least two behavioral cycles of the application.--re-time-delta-hours: This parameter specifies the UTC offset value of the time zone where the application is located, the replica number recommendation algorithm needs to sense the time zone information to learn the time features.--re-test-dataset-size-in-seconds: This parameter specifies the test set size of the replica recommendation algorithm learning, default is one day (86400), only when the historical length is less than one day do you need to shorten it, such as setting it as one hour (3600) in this example.--scaling-freq: This parameter specifies the accuracy of the final replica number prediction result of the algorithm, that is, the maximum frequency of actual scaling, so it cannot be shorter than the original prediction accuracy of the timeseries forecasting algorithm (thefreqparameter used in timeseries forecasting model training). The algorithm will resample the original prediction result by the maximum value according to the given accuracy and output it. For example, if this parameter is set to 1 hour, the algorithm will finally give the maximum number of replicas needed by this workload every hour, and finally this workload will scale up and down at most once an hour.
Execute the following command to create this IHPA:
kubectl apply -f dynamic-predictive-portrait-sample.yaml
Verify results
- Verify that IHPA automatically created a CronJob to run the algorithm task, and the last task ran successfully:
kubectl get cj -n kapacity-system
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
default-predictive-sample-predictive 0/30 * * * * False 1 26m 2d1h
kubectl get job -n kapacity-system
NAME COMPLETIONS DURATION AGE
default-predictive-sample-predictive-28286564 1/1 16s 28m
- Verify that the algorithm result was successfully written to the predictive horizontal portrait of IHPA:
kubectl get hp predictive-sample-predictive -o yaml
apiVersion: autoscaling.kapacitystack.io/v1alpha1
kind: HorizontalPortrait
metadata:
name: predictive-sample-predictive
namespace: default
...
spec:
...
status:
conditions:
- lastTransitionTime: "2023-10-25T11:00:00Z"
message: portrait has been successfully generated
observedGeneration: 1
reason: SucceededGeneratePortrait
status: "True"
type: PortraitGenerated
portraitData:
expireTime: "2023-10-25T11:30:00Z"
timeSeries:
timeSeries:
- replicas: 4
timestamp: 1698231600
- replicas: 3
timestamp: 1698232200
- replicas: 2
timestamp: 1698232800
type: TimeSeries
- Verify that IHPA has adjusted the replica count of the workload according to the prediction result of the algorithm:
kubectl describe ihpa predictive-sample
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning NoValidPortraitValue 29m (x10 over 85m) ihpa_controller no valid portrait value for now
Normal UpdateReplicaProfile 25m ihpa_controller update ReplicaProfile with onlineReplcas: 1 -> 4, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 15m ihpa_controller update ReplicaProfile with onlineReplcas: 4 -> 3, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 5m9s ihpa_controller update ReplicaProfile with onlineReplcas: 3 -> 2, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Cleanup
Run following command to cleanup all the resources:
kubectl delete -f dynamic-predictive-portrait-sample.yaml
kubectl delete -f periodic-client.yaml
kubectl delete -f nginx-ingress.yaml
kubectl delete -f nginx-statefulset.yaml
1.4 - Multi-Stage Gray Scaling
Before you begin
You need to have a Kubernetes cluster with Kapacity installed.
Run sample workload
Download nginx-statefulset.yaml and run following command to run an NGINX workload:
kubectl apply -f nginx-statefulset.yaml
Check if the workload is running:
kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-0 1/1 Running 0 5s
Create IHPA with gray scale down strategy
Download gray-strategy-sample.yaml which looks like this:
apiVersion: autoscaling.kapacitystack.io/v1alpha1
kind: IntelligentHorizontalPodAutoscaler
metadata:
name: gray-strategy-sample
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: StatefulSet
name: nginx
minReplicas: 1
maxReplicas: 10
portraitProviders:
- priority: 1
static:
replicas: 1
type: Static
- cron:
crons:
- name: cron-1
replicas: 5
start: 0 * * * *
end: 10 * * * *
priority: 2
type: Cron
behavior:
scaleDown:
grayStrategy:
grayState: Cutoff # GrayState is the desired state of pods that in gray stage.
changeIntervalSeconds: 30 # ChangeIntervalSeconds is the interval time between each gray change.
changePercent: 50 # ChangePercent is the percentage of the total change of replica numbers which is used to calculate the amount of pods to change in each gray change.
observationSeconds: 60 # ObservationSeconds is the additional observation time after the gray change reaching 100%.
This IHPA contains below two portrait providers:
- A static portrait provider with priority 1 and a static replica number 1.
- A cron portrait provider with priority 2 and replica number 5 which takes effect the 0th minute to the 10th minute of every hour.
Note that the cron portrait provider’s priority is higher than the static one, so the replica number it provided would override the one provided by the static portrait provider when it is effective.
Run following command to create the IHPA:
kubectl apply -f gray-strategy-sample.yaml
Verify results
We can see that the cron portrait provider is taking effect at 0~10th minute of every hour, and the replicas of the workload are scaled up from 1 to 5:
kubectl get po -L 'kapacitystack.io/pod-state' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES POD-STATE
nginx-0 1/1 Running 0 50m 10.1.5.52 docker-desktop <none> 1/1
nginx-1 1/1 Running 0 56s 10.1.5.68 docker-desktop <none> 1/1
nginx-2 1/1 Running 0 54s 10.1.5.69 docker-desktop <none> 1/1
nginx-3 1/1 Running 0 52s 10.1.5.70 docker-desktop <none> 1/1
nginx-4 1/1 Running 0 50s 10.1.5.71 docker-desktop <none> 1/1
The number of endpoints of the service of the workload is also changed to 5:
kubectl get ep nginx
NAME ENDPOINTS AGE
nginx 10.1.5.52:80,10.1.5.68:80,10.1.5.69:80 + 2 more... 3d3h
At the 10th minute, we can see that 2 pods change to Cutoff state and are removed from the endpoints of the service:
kubectl get po -L 'kapacitystack.io/pod-state' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES POD-STATE
nginx-0 1/1 Running 0 51m 10.1.5.52 docker-desktop <none> 1/1
nginx-1 1/1 Running 0 63s 10.1.5.68 docker-desktop <none> 1/1
nginx-2 1/1 Running 0 61s 10.1.5.69 docker-desktop <none> 1/1
nginx-3 1/1 Running 0 59s 10.1.5.70 docker-desktop <none> 0/1 Cutoff
nginx-4 1/1 Running 0 57s 10.1.5.71 docker-desktop <none> 0/1 Cutoff
kubectl get ep nginx
NAME ENDPOINTS AGE
nginx 10.1.5.52:80,10.1.5.68:80,10.1.5.69:80 3d3h
After waiting for another 30 seconds, we can see that the 4 pods change to Cutoff state and are removed from the endpoints of the service:
kubectl get po -L 'kapacitystack.io/pod-state' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES POD-STATE
nginx-0 1/1 Running 0 51m 10.1.5.52 docker-desktop <none> 1/1
nginx-1 1/1 Running 0 96s 10.1.5.68 docker-desktop <none> 0/1 Cutoff
nginx-2 1/1 Running 0 94s 10.1.5.69 docker-desktop <none> 0/1 Cutoff
nginx-3 1/1 Running 0 92s 10.1.5.70 docker-desktop <none> 0/1 Cutoff
nginx-4 1/1 Running 0 90s 10.1.5.71 docker-desktop <none> 0/1 Cutoff
kubectl get ep nginx
NAME ENDPOINTS AGE
nginx 10.1.5.52:80 3d3h
After waiting for another 1 minute, we can see that the replicas of the workload are finally scaled down to 1:
kubectl get po -L 'kapacitystack.io/pod-state' -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES POD-STATE
nginx-0 1/1 Running 0 52m 10.1.5.52 docker-desktop <none> 1/1
You can also see the entire process of scaling by checking events of the IHPA:
kubectl describe ihpa gray-strategy-sample
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal CreateReplicaProfile 3m53s ihpa_controller create ReplicaProfile with onlineReplcas: 1, cutoffReplicas: 0, standbyReplicas: 0
Normal UpdateReplicaProfile 2m44s ihpa_controller update ReplicaProfile with onlineReplcas: 1 -> 5, cutoffReplicas: 0 -> 0, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 104s ihpa_controller update ReplicaProfile with onlineReplcas: 5 -> 3, cutoffReplicas: 0 -> 2, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 74s ihpa_controller update ReplicaProfile with onlineReplcas: 3 -> 1, cutoffReplicas: 2 -> 4, standbyReplicas: 0 -> 0
Normal UpdateReplicaProfile 14s ihpa_controller update ReplicaProfile with onlineReplcas: 1 -> 1, cutoffReplicas: 4 -> 0, standbyReplicas: 0 -> 0
Cleanup
Run following command to cleanup all the resources:
kubectl delete -f gray-strategy-sample.yaml
kubectl delete -f nginx-statefulset.yaml